Optical character recognition (OCR) converts text in a scanned document or image into a machine-readable text.

History of OCR: The earliest usage of OCR was to help blind people read. OCR helped machines read text that was converted into sound. One such machine was the Optophone invented by Edmund Edward Fournier d’Albe in 1913. By the 1960s, the U.S. Postal Service was using OCR to help sort the mail. Corporate America began using OCR to scan price tags in the 1960s. Now, it is used in a multitude of different sectors and devices.
There are four basic steps to OCR: pre-processing, breaking down the text into characters, recognizing the characters, and producing the final output.
Pre-processing: The goal of the pre-processing step is to identify the lines of clear text. In order to identify the lines, the structure of the document (image, column, table, etc.) needs to be determined. Additionally, the image or scan needs to be adjusted for brightness, color, and sharpness to help locate the lines of text.

Break down text into characters: After isolating the lines of text in the previous step, each line is broken down into words and then characters. Pixels are used to determine if there is a space between words and then a smaller space between characters. In some versions of OCR, pixels are also used to create a matrix of the character, with 0 representing a white pixel and 1 representing a colored pixel.

Recognize Characters: Now that all the characters have been identified, the algorithm has to recognize or match them to known characters. This is done by comparing them to a library of commonly used fonts. If the characters are represented by a matrix, matrix matching is used to recognize characters. In more advanced forms of OCR, context clues from surrounding characters are also used to identify the character. For example, the “l” in “hills” can be either “1” or “l”, the surrounding letters would help recognize the letter “l” appropriately
Final Output: The recognized characters are put into the same structure as the original image or scan and is outputted as machine-readable e.g pdf, excel, document, text file, etc.

Variants of OCR:
OCR is a both an umbrella term for different forms of text conversion and a specific form of text conversion. The umbrella term can encompass the following:
- Optical Character Recognition: works by identifying characters in type-written text
- Optical Word Recognition: works by identifying words in type-written text
- Optical Mark Recognition: works by identifying human-filled marks or patterns in a type-written form e.g. a scantron
- Intelligent Character Recognition: works by identifying characters in hand-written or cursive text
- Intelligent Word Recognition: works by identifying words in hand-written or cursive text
Available OCR Software: Tesseract is an open-source software that can be used with Python. Other free softwares: GOCR, CuneiForm, Kraken, and A9T9. Paid softwares: OmniPage Ultimate, ABBYY FineReader PDF, Kofax, PrecisionOCR , Nanonets OCR, Rossum, and Readiris.
Testing one OCR software: Use the mobile version of ABBYY FineScanner to see how well it works. I used historical documents that I have digitized by hand, so I wanted to see if there is a faster was to digitize them. These documents happen to be in tabular form so it is also a good test to see if the software can identify structure well. The first document is a 1893 bank report. It is a scanned image from the California Bank Commissioner. The software converted the top-half of the page into a table outputted into a document, but the bottom-half was not fully converted. The list of counties was not readable, so the software just used an image of the names of the counties instead.


The second bank report from the 1892 Bank Commissioner Report did even worse. None of the table was converted into machine-readable text, the software just took an image of the table and put it into a document.
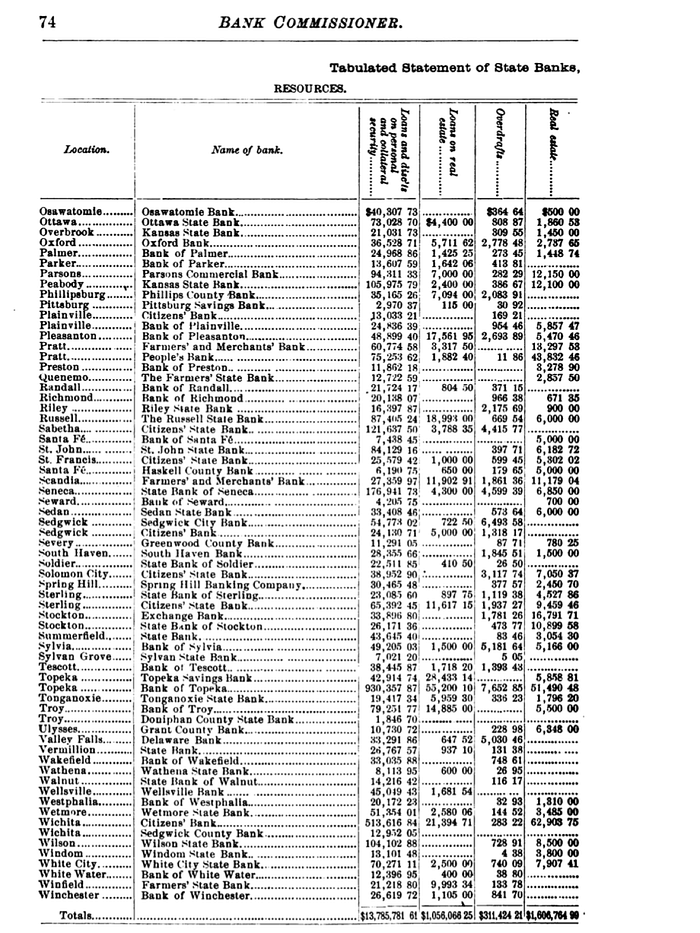
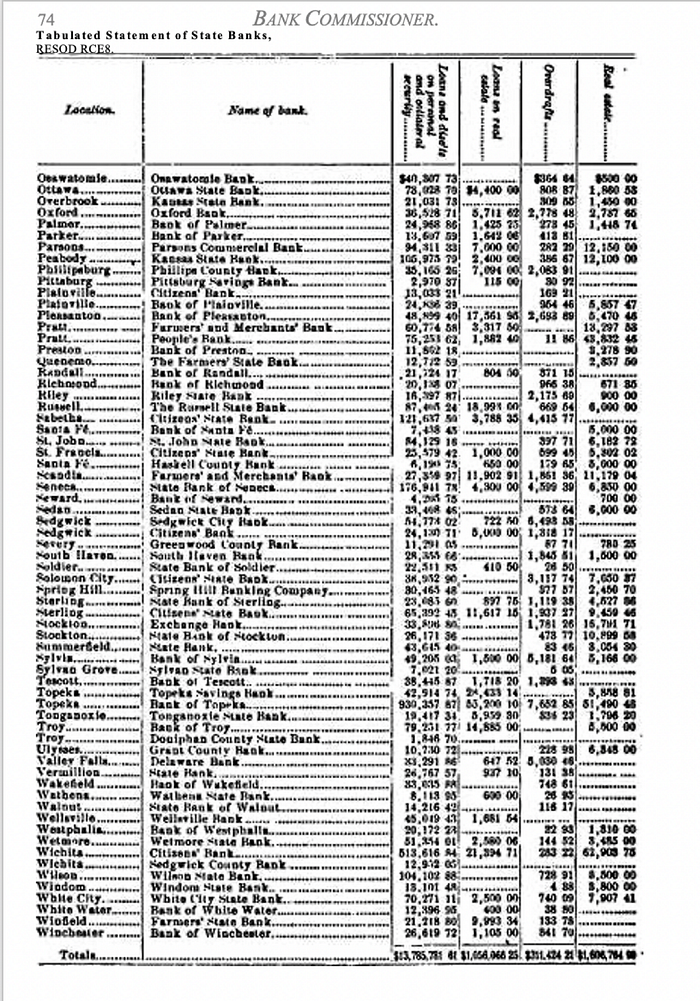
Considering I did not adjust the scanned image for brightness, contrast, or color, the ABBYY FineScanner app did a decent job for at least one document. In the future, I will try digitizing these documents with Tesseract, so I can compare the performances across softwares.
